

我经常被问到故事点和小时数的关系。提问者经常期待我像这样回答
“一个故事点=8.3小时”。好吧,事实并非如此(尤其是我用了8.3这个数字)。来,让我们看看敏捷故事点和小时数之间的真正关系吧。
假设因为某些原因你跟踪了一个团队一段时间,来查看他们开发的每个1个故事点的用户故事。如果你把相关数据做成图的话大概会是这个样子:
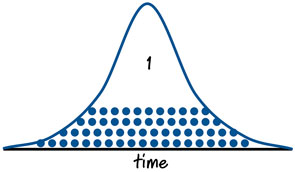
可以看出,一些用户故事比另一些用户故事花费更多,有些则相反,但总体看来,一个故事点的用户故事花费的时间是呈大家比较熟悉的正态分布的。
现在假设你还跟踪了解了2个故事点用户故事的时间消耗情况。同样的画出数据图,你看到的可能是这个样子的:
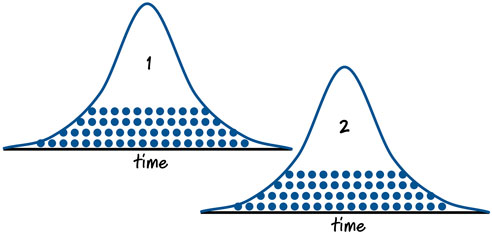
如果一个故事点的用户故事分布在平均值x周围,理想情况下,二个故事点的用户故事将分布在平均值2x附近。当然,事实上不会刚好是这个样子,但是,如果一个团队估算做的特别好的话,会很接近这个数字,他们由此估算也得到了一个比较可靠的计划。
从上面两幅图,我们看出故事点和小时数见的关系是一个分散的对应关系。一个故事点对应着于一个平均值x及其周围的正态分布。当然,对于2个故事点也是这样的,其他也是。
顺便说明一下,请注意我画的一个故事点和二个故事点的正态分布图上2端尾巴上是有重叠的。被团队估算为一个故事点的最大用户故事是完全有可能比估算为2个故事点的最小用户故事花费更多的时间的。
毕竟,没有哪个团队能有完美的洞察力来估算,尤其是在故事点级别。所以,如果说1个故事点和2个故事点的正态分布2端尾巴会重叠的话,那么,一个故事点和31个故事点的正态分布会重叠是不太可能的。
(Scrum 中文网经授权翻译及转载,不得复制)






-Professional.png)





